Enabling OpenMP tasking in iPIC3D¶
Implementation details¶
In order to port the version of iPIC3D based on MPI_THREAD_MULTIPLE to the task-based version, the existing for-loops in the particles/Particles3Dcomm.cpp and particles/Particles3D.cpp files were re-written with the use of
#pragma omp task
In general, there are two options of how to change for-loops to enable tasking:
1) Single task producer
void foo(float* x, float* y, float a, int n)
{
#pragma omp parallel
{
#pragma omp single
{
for (int i = 0; i < n; i++)
#pragma omp task
{
y[i] = y[i]+a*x[i];
}
}
}
}
This is a common pattern, but it is NUMA unfriendly. Here the “#pragma omp single” directive allows only one thread to execute the for-loop, while the rest of the threads in the team wait at the implicit barrier at the end of the “single” construct. At the each iteration, a task is created.
2) Parallel task producer
void bar(float* x, float* y, float a, int n)
{
#pragma omp parallel
{
#pragma omp for
{
for (int i = 0; i < n; i++)
#pragma omp task
{
y[i] = y[i]+a*x[i];
}
}
}
}
This approach is more NUMA friendly and it was used for iPIC3D. Here the task creation loop is shared among the threads in the team.
Scaling tests¶
In this section we will discuss the performance results from the weak scaling tests. Tests were performed on the Beskow supercomputer at the PDC Center for High Performance Computing at the KTH Royal Institute of Technology. To compare the original version of the iPIC3D code (based on pure MPI) with the new version (based on OpenMP tasking) we used two standard simulation cases called GEM 3D and Magnetosphere 3D. In addition, we used two different data sizes/regimes for both simulation cases:
- Field solver dominated regime. Here, a relatively small number of particles (27 per cell) is used. The most computationally expensive part of the iPIC3D code results in the Maxwell field solver.
- Particle dominated regime. It is characterised by a large number of particles (1,000 per cell). The most computationally expensive part of the iPIC3D code results in the particle mover.
Thus, there were four different cases (two simulation versions with two regimes). Each of these simulations has been executed on the increasing number of cores from 32, 64, 128 and up to 256 cores. The presented results here are for the cases with two, four and eight OpenMP threads. In order to ensure a fair comparison, the number of iterations in the linear solver was fixed to 20, although in a real simulation the number of iterations depends on the speed of convergence.
Figure 1, Figure 2, Figure 3 and Figure 4 show the results of the weak scaling tests for each of the four cases. Three-dimensional decomposition of MPI processes on X-, Y- and Z-axes was used, resulting in different topologies of MPI processes, each having two, four, and then eight threads in addition. The total number of particles and cells in a simulation are calculated from nxc*nyc*nzc*npcelx*npcely*npcelz and nxc*nyc*nzc, respectively. Thus, for example, for the particle dominated Magnetosphere 3D simulation on 32 cores (2x2x2 MPI processes x 4 OpenMP threads), there were used 27x106 particles and 30x30x30 cells, and the simulation size increased proportionally to the number of processes.
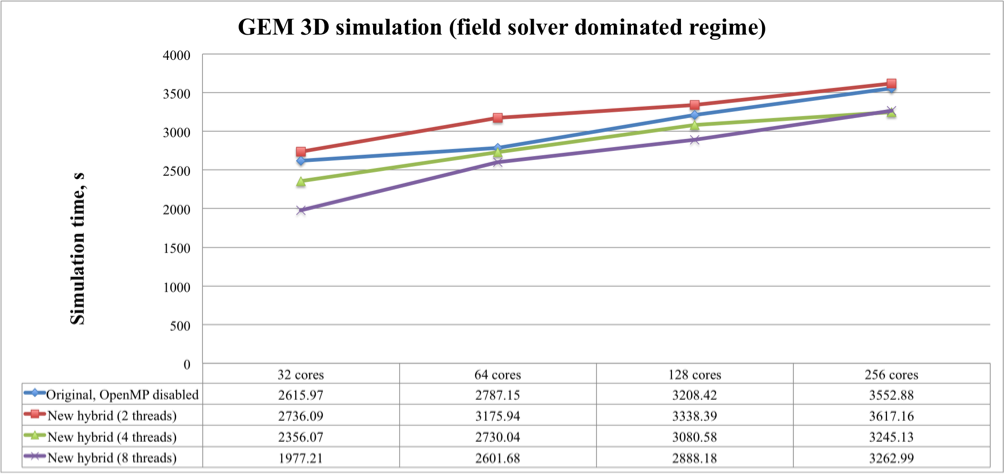
Figure 1. Weak scaling test for the field solver dominated GEM 3D simulation of the original and new versions of the iPIC3D code
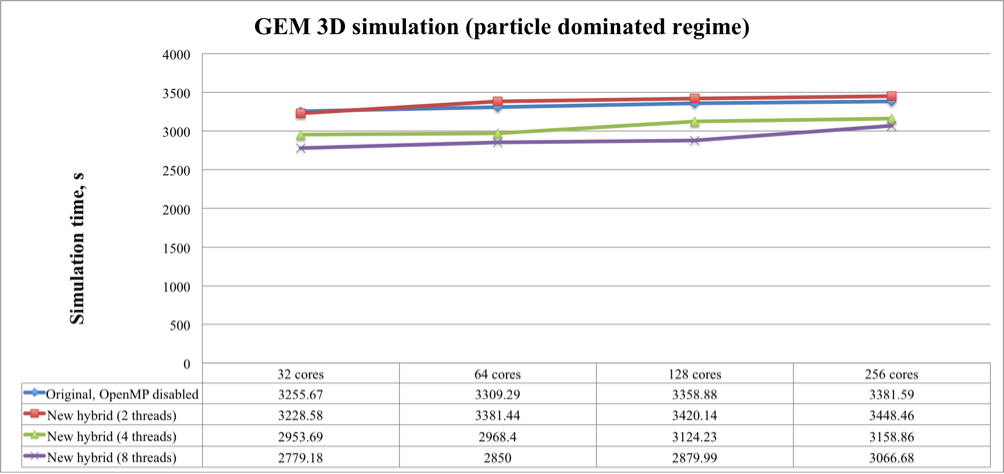
Figure 2. Weak scaling test for the particle dominated GEM 3D simulation of the original and new versions of the iPIC3D code
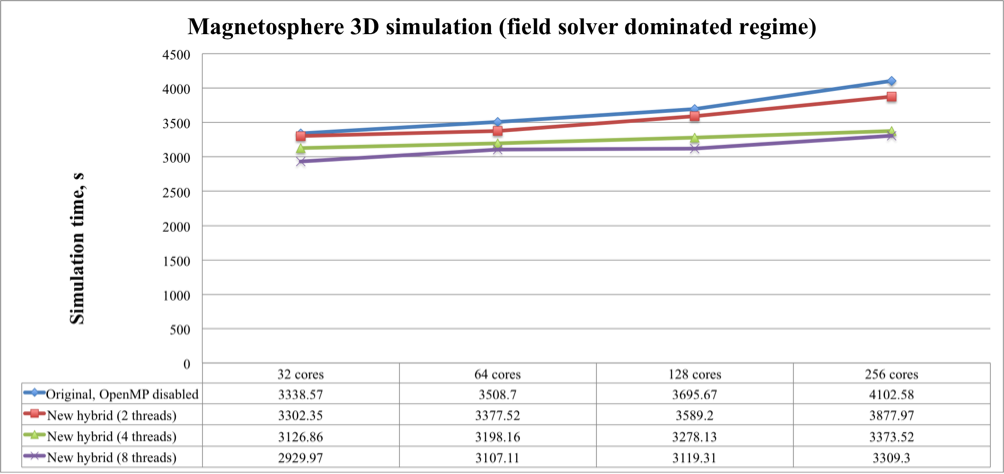
Figure 3. Weak scaling test for the field solver dominated Magnetosphere 3D simulation of the original and new versions of the iPIC3D code
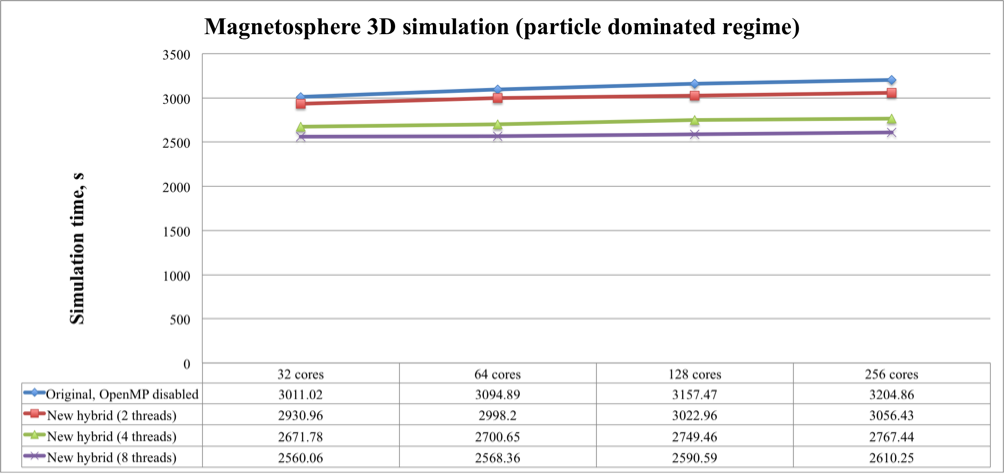
Figure 4. Weak scaling test for the particle dominated Magnetosphere 3D simulation of the original and new versions of the iPIC3D code
These figures show that the original iPIC3D code with disabled OpenMP (meaning pure MPI) and the new version with two threads per one MPI process had the longest execution time. The task-based version with eight threads per one MPI process is always faster than with two or four threads. On 256 cores it shows 9-15% of speedup comparing to the pure-MPI-based version and 9-14% when comparing to the tasked-based version with two threads per one MPI process.